
Python has become increasingly useful in the world of data extraction, specifically in web scraping.
Whenever you start a web scraping project, choosing the right tool is very important.
If you’re familiar with jQuery, PyQuery is an excellent choice due to its similar syntax and intuitive nature.
What Is PyQuery?
PyQuery is a jQuery-like library for Python. It allows you to extract and manipulate data from HTML and XML documents.
I just liked the jquery API and I missed it in python so I told myself “Hey let’s make jquery in python”. This is the result.
PyQuery Documentation
PyQuery has a good performance and has similar syntaxes and functionalities as jQuery making it especially easy to use for web developers and those who are familiar with jQuery.
You can learn more about PyQuery’s syntaxes in its documentation.
Getting Started
Let’s dive into a hands-on example by scraping a sandbox website, scrapethissite.com which provides a list of countries for you to scrape.
Open up your favorite text editor. You can use a Jupyter Notebook, VS Code or any editor of your choice. You can just follow the code from top to bottom.
First, ensure you have the necessary libraries installed.
Any library you don’t yet have can be installed with pip install [library]
import csv
from pyquery import PyQuery as pq
import requestsThen, define the essential variables for the scraping process.
url = 'https://www.scrapethissite.com/pages/simple' # The URL to be scraped
response = requests.get(url) # Retrieving the HTML content
source = pq(response.content) # Parsing the HTML content using PyQuery
columns = ['name', 'capital', 'population', 'area'] # Table headers
dataSet = [] # Stored data that will be exported as csvScraping The Title
Let’s start with a light warm up, extract the title of the page using the following code.
print(source.find('title').text()) # Countries of the World: A Simple Example | Scrape This Site | A public sandbox for learning web scrapingWe’re using source.find(”) to locate where we want to extract the data from. In this case, the title tag. You can implement this with other tags or even classes (add . before the class name) and ids (add # before the id), just like in JQuery.
Simple, right? It’s especially intuitive if you’re familiar with JQuery.
Extracting Country Data
If you inspect the element, you can see that each country is wrapped inside a div with “col-md-4 country” classes. So, that’s where we’ll extract from.
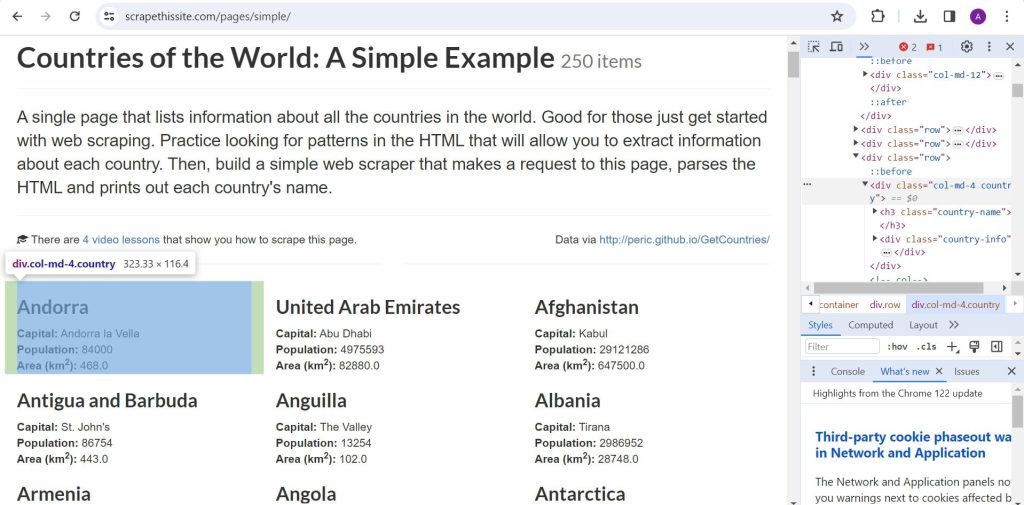
We’ll get all elements with those classes and loop through them to extract the data or texts inside.
countries = source.find('.col-md-4.country')
for country in countries.items():
name = country.find('h3').text()
capital = country.find('.country-capital').text()
population = country.find('.country-population').text()
area = country.find('.country-area').text()
dataSet.append([name, capital, population, area])Now, if you inspect the div again, you can see that the data we want are wrapped inside other tags, which are h3, .country-capital, .country-population and .country-area. Get the text from all those elements.
Append each row of data into the dataSet which is used to store all the scraped data and will be exported as CSV later.
Export To CSV
Finally, we will export the scraped data to CSV.
def writeto_csv(data, filename, columns):
with open(filename, 'w+', newline='', encoding="UTF-8") as file:
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
writer = csv.writer(file)
for element in data:
writer.writerows([element])
writeto_csv(dataSet, 'countries.csv', columns)Full Code
import csv
from pyquery import PyQuery as pq
import requests
url = 'https://www.scrapethissite.com/pages/simple'
response = requests.get(url)
source = pq(response.content)
columns = ['name', 'capital', 'population', 'area']
dataSet = []
print(source.find('title').text())
countries = source.find('.col-md-4.country')
for country in countries.items():
name = country.find('h3').text()
capital = country.find('.country-capital').text()
population = country.find('.country-population').text()
area = country.find('.country-area').text()
dataSet.append([name, capital, population, area])
def writeto_csv(data, filename, columns):
with open(filename, 'w+', newline='', encoding="UTF-8") as file:
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
writer = csv.writer(file)
for element in data:
writer.writerows([element])
writeto_csv(dataSet, 'countries.csv', columns)Conclusion
That’s how you can scrape a website with PyQuery.
You can use this tutorial as a reference to scrape other websites.
Practice is the key to mastering web scraping.
I have another beginner friendly tutorial scraping the same website with lxml, it could be suitable for you if you want to increase your arsenal of web scraping tools. Check out my tutorial on web scraping with lxml.
Happy scraping!