
As a blogger and developer, staying informed about the latest trends and topics in your niche is essential.
Getting a complete and easy to view list of what your competitors write will certainly be useful.
However, manually scouring through numerous blog pages can be time-consuming.
Fortunately, there’s a more efficient solution : scraping sitemaps using Python.
In this guide, I’ll walk you through the process of extracting blog titles from a sitemap and exporting them into a CSV file.
Note : If you aren’t familiar about scraping yet, I recommend you first read my beginner friendly guide on web scraping with lxml and Python.
Goal And Overview
Before we dive into the code, let’s outline our goal and import the necessary libraries.
Our objective is to scrape all the blog titles and URLs listed in a sitemap and save them in a CSV format.
For practice, we’ll use HubSpot’s sitemap.
We’ll be using the lxml library for parsing XML, requests for fetching the sitemap, and csv for exporting the scraped data into CSV.
One final thing to do before we can dive into the code is analyzing the target sitemap. We have to identify what to scrape and where are they located.
Analyzing HubSpot’s Sitemap
Let’s take a quick look at HubSpot’s sitemap.xml.
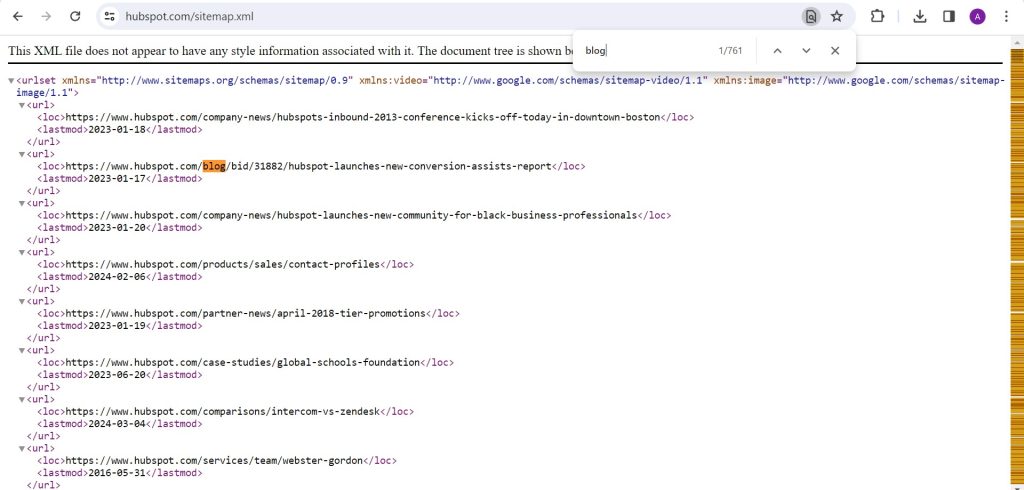
What we want to extract are the URLs containing blog and later also clean the URLs into the title. Then, we will export those extracted data to CSV.
The URLs are located inside the <loc> tags, so that’ll be our XPath.
//loc/text()But, there’s still one problem.
Scraping XML is a bit different form scraping HTML, there’s a rule or convention we have to follow.
If we look back at the sitemap, in the <urlset> tag at the top there’s and attribute called xmlns=”http://www.sitemaps.org/schemas/sitemap/0.9″.
That attribute refers to XML Namespaces, a convention or rule the XML must follow.
To follow the rule, we have to modify our XPath.
namespaces = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
urls = sitemap.xpath("//ns:loc/text()", namespaces=namespaces)Now, we are ready to dive into the code, starting from the beginning.
Importing The Libraries
First, let’s import the libraries we’ll use.
Open up your preferred code editor (it can be VS Code or Jupyter Notebook) and import all the necessary packaged. Any packages you don’t yet have can be installed by entering pip install [package-name] in your terminal.
from lxml import etree
import requests
import csvImportant Variables
Let’s define a few important variables.
url = "https://www.hubspot.com/sitemap.xml" #target URL to be scraped
columns = ['url', 'title'] #headers for the CSV
dataSet = [] #where we'll store the scraped data and will be exported as CSVFetching The URL
The code below will fetch the target URL.
response = requests.get(url)
sitemap_content = response.text
sitemap = etree.fromstring(sitemap_content.encode())
namespaces = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
urls = sitemap.xpath("//ns:loc/text()", namespaces=namespaces)The requests library will retrieve the content of the webpage (in XML format), which will then be stored in the sitemap_content variable. The etree.fromstring() method from the lxml library is used to parse this XML content into a structured tree format, which enables the extraction of specific elements.
We then define the namespaces and the XPaths to locate where to extract data from just like what we discussed above.
The extracted URLs are stored in the urls variable, which will be looped through to be processed in the next part.
Scraping The Data
In this part, we will loop through the urls variable and store the blog URLs and titles into dataSet variable.
To filter and extract only the blog titles and URLs, we use an if block to check if the URL contains ‘blog’ in it marking that it is indeed a blog post. If it is, we will process it further.
Getting the blog title requires cleaning the URL by removing the unnecessary characters such as /, – and white spaces.
Finally, we will store the filtered URLs and the cleaned titles into the dataSet.
for url in urls:
if 'blog' in url:
title = url.split('/')[-1].replace('-', ' ').replace('/', '').title()
dataSet.append([url, title])Export As CSV
After all is done, we can export the dataSet as CSV.
def writeto_csv(data, filename, columns):
with open(filename, 'w+', newline='', encoding="UTF-8") as file:
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
writer = csv.writer(file)
for element in data:
writer.writerows([element])
writeto_csv(dataSet, 'sitemap.csv', columns)Result
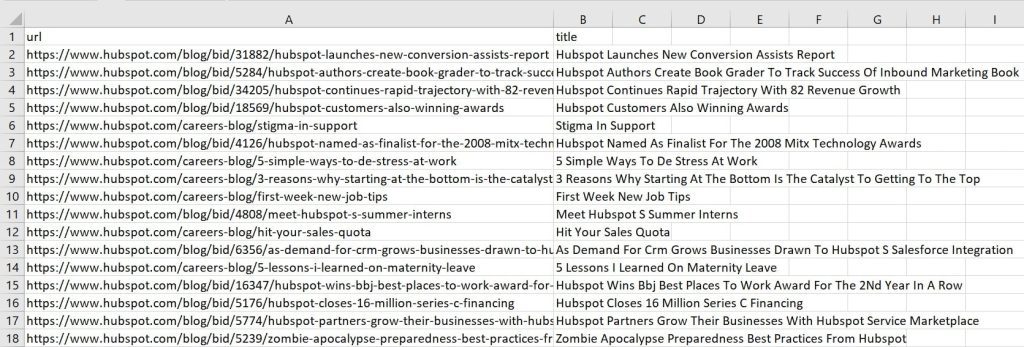
Now, we have our CSV containing the Blog URLs and titles from the sitemap.
Here’s an example of the result.
You can see that only URLs containing ‘blog’ in it is included.
Full Code
from lxml import etree
import requests
import csv
url = "https://www.hubspot.com/sitemap.xml"
columns = ['url', 'title']
dataSet = []
response = requests.get(url)
sitemap_content = response.text
sitemap = etree.fromstring(sitemap_content.encode())
namespaces = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
urls = sitemap.xpath("//ns:loc/text()", namespaces=namespaces)
for url in urls:
if 'blog' in url:
title = url.split('/')[-1].replace('-', ' ').replace('/', '').title()
dataSet.append([url, title])
def writeto_csv(data, filename, columns):
with open(filename, 'w+', newline='', encoding="UTF-8") as file:
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
writer = csv.writer(file)
for element in data:
writer.writerows([element])
writeto_csv(dataSet, 'sitemap.csv', columns)Conclusion
That’s an example of how you can scrape or parse a sitemap.
Be aware though that not all sitemaps can be scraped with this code since some sitemaps have different structure.
You can use this tutorial as a basic understanding and explore how to scrape other sitemaps.
Happy scraping!