Web scraping is very useful but can be a bit daunting, especially for beginners. So, in this tutorial, I will show you a simple and beginner-friendly method to scrape a website with NodeJS.
What we’ll learn
In this tutorial, we will learn how to scrape a website with NodeJS.
For practice, we will scrape books.toscrape.com. It is a dummy book store website that is specially made for web scraping practice just like the name suggests.
We will learn how to identify and extract specific data from the website.
Prerequisites
Before diving into the project, make sure you have Node.js and npm installed. You will need it to run the code.
To check if you have Node.js and npm installed, just run these commands in your terminal tou check both your Node.js and npm versions respectively.
node -v
npm -vIf you haven’t installed them, you can download Node.js from its official website. It comes automatically with npm.
Steps
Let’s break down the process into several steps.
Step 1 : Create the project directory
First of all, create a folder, you can name it anything. I’ll name it scraping basic.
Open terminal (command prompt), go (cd) to that directory and run this command.
npm init -yThis will initialize your nodejs project and create a package.json file which contains basic information about your project and the libraries you use.
Note : the -y or yes flag accept the prompts that come from npm init automatically.
Step 2 : Install the libraries/dependencies
There are many libraries for web scraping in Node.js. For this tutorial, we’ll use the easiest ones and gradually increase the complexity in the next tutorials.
These are the main and basic libraries you need :
- Axios – A library for sending HTTP requests.
- Express- A Node.js framework. You can scrape without Express, but it is more convenient using it.
- Cheerio – A library for parsing and manipulating HTML or to put it simply, extracting data from a website. Cheerio’s syntax is similar to jQuery’s so it’d be easy to understand since most of you are most likely familiar with jQuery. Cheerio is an essential and beginner-friendly library for web scraping.
Those are the basic libraries we need for this tutorial.
To install all 3, run the command below and they will be installed for you.
npm install axios cheerio expressStep 3 : Set Up Your Express App
Before we scrape a website, we need an app to run. Let’s set up our express app.
Create index.js and write this code.
// Defining the port where we run our app, example : http://localhost:5000. Feel free to change it
const PORT = 5000;
// Importing the libraries we need
const axios = require('axios');
const cheerio = require('cheerio');
const express = require('express');
// Initializing our express app
const app = express();
// Defining the URL we scrape from
const url = 'https://books.toscrape.com/';
// scraping script will be here
// Running our express app
app.listen(PORT, () => console.log(`Server running on PORT ${PORT}`));What we did was initializing the constants we need and running our express app. I added comments in the code as explanations. You can delete the comments to keep the code neat.
Step 4 : Determine the scrape target
Scraping basically means extracting specific data we want from a website.
It could be the title, emails or even the list of products from the website.
Let’s go to the page that we want to scrape from and inspect the element we want to scrape.
For example, let’s get the title of the page.
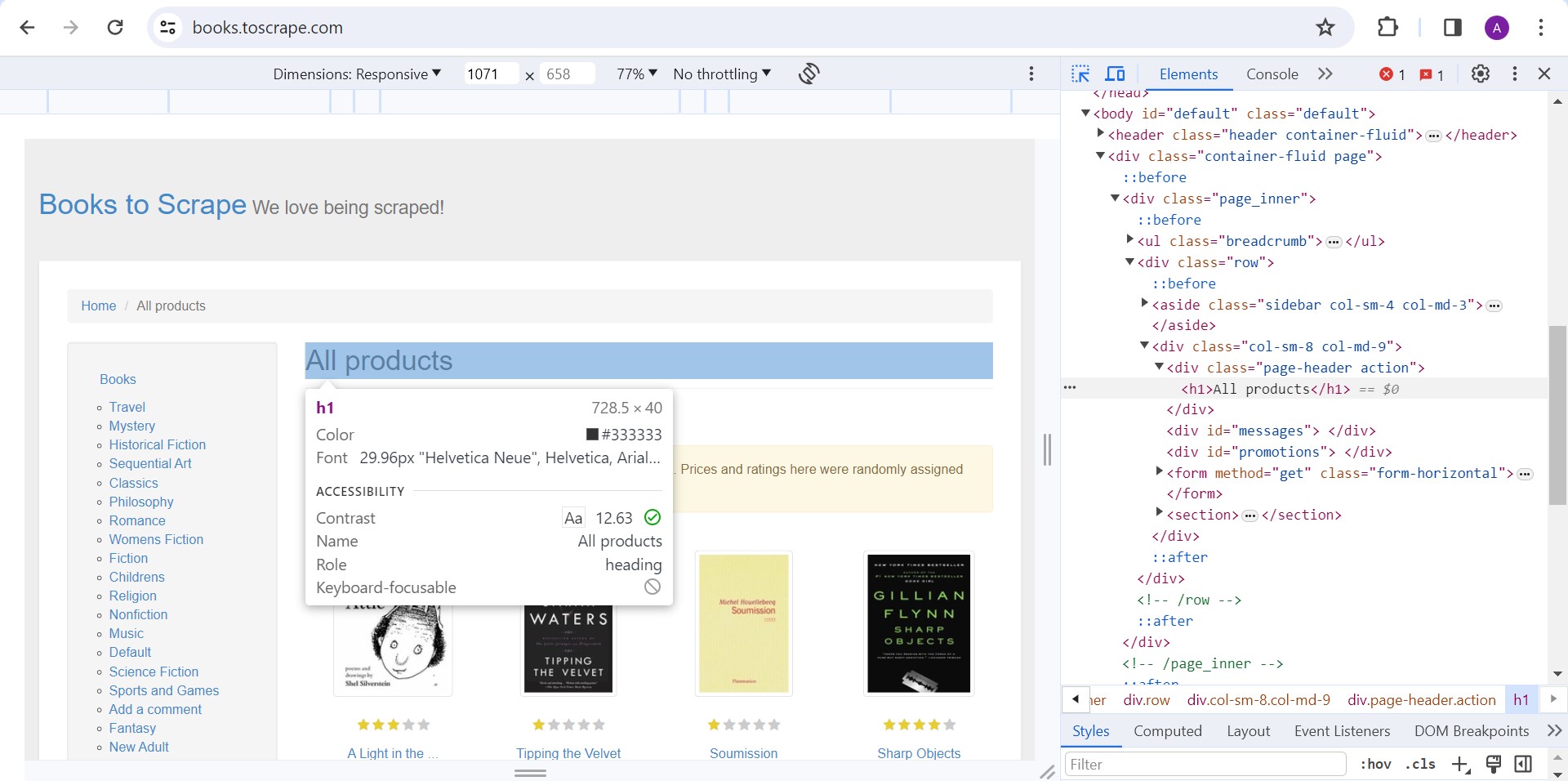
We can see that the main title of the page is ‘All products’ which is located in the h1 tag. Keep this tag in mind as we will scrape it with Node.js
Let’s look for other interesting data to scrape.
You may try to locate where the book title and price are located with inspect element. I’ll discuss it in the next step.
Step 5 : Scrape the website
Now, let’s get the page title
const PORT = 5000;
const axios = require('axios');
const cheerio = require('cheerio');
const express = require('express');
const app = express();
const url = 'https://books.toscrape.com/';
axios(url) // making HTTP GET request to the specified URL
.then(response => { // Handling the promise
// the full HTML script. You can try logging it to unserstand more
const html = response.data;
// loading HTML with cheerio so that the HTML tags can be called with jQuery-like syntax
const $ = cheerio.load(html);
// Extracting the text from h1 tag, which is 'All Products'
const page = $('h1').text();
console.log(page);
}).catch(err => console.log(err)); // Handling the error
app.listen(PORT, () => console.log(`Server running on PORT ${PORT}`));You have successfully scraped the page title from the h1 tag!
Now, we’ll try to scrape the list of book titles and their prices and store it in an array of objects.
Inspect the website again but this time, find where the titles and prices are contained.
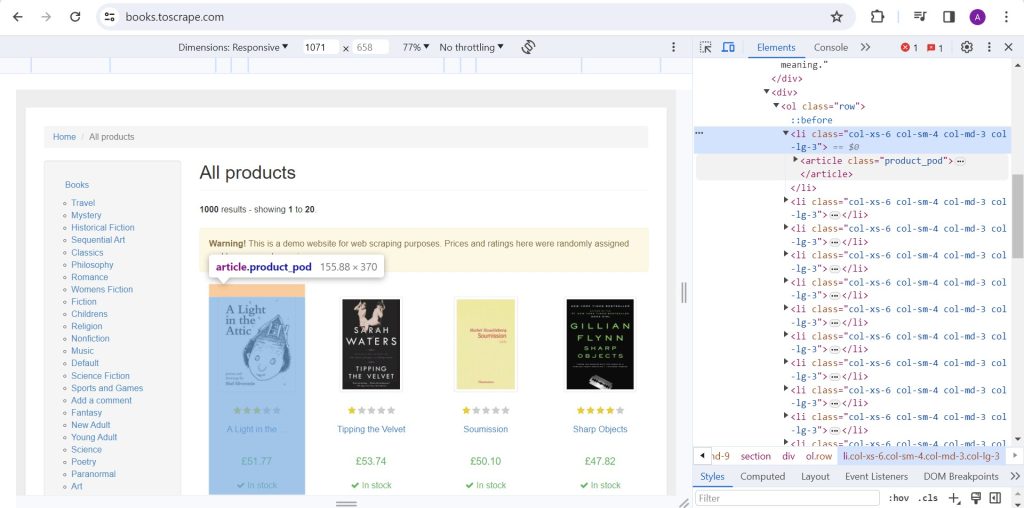
You can see that book titles and prices are wrapped inside articles with product_pod class. We will get each product_pod and loop through all of them to extract the titles and prices.
If you look again, you will see that the title is located inside a tag which is wrapped inside h3 and the price is located inside price_color class.
Let’s loop through and extract all of them.
const PORT = 5000;
const axios = require('axios');
const cheerio = require('cheerio');
const express = require('express');
const app = express();
const url = 'https://books.toscrape.com/';
axios(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html);
const books = []; // array to store book titles and prices
$('.product_pod', html).each(function() { // loop through each product pod
const title = $(this).find('h3 a').text(); // extract the title
const price = $(this).find('.price_color').text(); // extract the price
books.push({title, price}) // store them inside the array
});
console.log(books); // log the array
}).catch(err => console.log(err));
app.listen(PORT, () => console.log(`Server running on PORT ${PORT}`));Now, you’ve successfully managed to scrape the list of books.
Conclusion
Congratulations! You’ve built a basic web scraper with Node.js.
Of course, there are still lots of stuffs to improve and add.
To make the scraped data useful in real applications, you can wrap the code inside a function and return the scraped data instead of console logging it.
Other than that, we have to deal with paginations and dynamic data (websites built with React for example) which I will cover in the future.
Luckily, there are tools like ScrapingBee that helps us to scrape websites easily.
Also, always remember that scraping data from a website is not always allowed. So, read the website’s Term of Service and make sure to be ethical.
I’ll cover more in the upcoming posts. You can comment to suggest on what topics about scraping that interest you.
Hope it helps!